Peer-to-Peer Alternative for Disseminating Web Information to Censoring Countries
By Keith Oxenrider
May 10, 2002
Revised and formated into HTML September 27, 2002
Introduction
There are some organizations that have a mandate to make information available to the citizens of other nations, particularly those whose governments are repressing free speech (such as China). Historically, some have done so by broadcasting radio into the restricted areas with powerful transmitters. With the advent of the Internet, this same information can be made available via a series of websites. With the introduction of this new technology comes the introduction of new ways to block dissemination. When radio is beamed into a country, the opposing government can install their own broadcast stations and either transmit noise or their own version of whatever is being sent from outside the borders, thus drowning out the outside signal. When the Internet is the vehicle, the information is typically screened via blocking the IP addresses of the sites deemed offensive. This creates a cat and mouse game where by changing the IP address (there are more than 2 billion available) one can circumvent the censorship, at least until the new IP address is discovered. This also creates a marketing issue of how to get the new IP address to the user community without notifying the censoring agency.
A key presumption made herein is that the focus on the use of the Internet to disseminate information is primarily via text with the possibility of some graphics, and not to make available the latest bells and whistles released in the browser wars.
This paper is broken down in several portions. The first portion (Overview) is a discussion of the issues surrounding the implementation of any Internet-based information dissemination method whose goal is to bypass censorship, along with some comments about possible policy ramifications. Second (Goals), a set of goals for any implementation is outlined. Third (Implementations), a discussion of some possible implementations along with some comments about pros and cons. And the final portion (Recommendation) outlines a specific implementation that addresses the goals and concerns listed in the Overview and Goals section and is specifically compared and contrasted with the Triangle Boy implementation.
I. Overview
Marketing the availability of any solution is critical and overrides all technical issues. The very act of attempting to inform the user community is, in many cases, also the act of informing the government agents dedicated to blocking the access. A good solution will be one where it is practically impossible to block all available lines of access without cutting off the cross border connections altogether while at the same time making the distribution of the available sites known to as wide an audience as possible.
To reduce the likelihood of the opposing governments incrementally investing to overcome the challenge from the incremental increase in complexity, if a solution were to present the government with a challenge of a sufficient magnitude, it is more likely to cause the internal management to quit rather than investing to overcome the challenge. While that sort of challenge may push the government into the extreme of entirely blocking cross border communication, in today’s global Internet-based economy that is likely to cost them substantially more than they stand to gain.
For policy and public relations reasons, it is very likely that an organization will want to institute an implementation that does not allow indiscriminant browsing of the Internet. The number and variety of sites available should of the inclusive variety, rather than exclusive. This means that rather than attempting to block sites deemed offensive (indeed, the same battle censoring countries are waging against content providers), the implementation should only allow traffic between a list of acceptable sites. That list may be in the hundreds, and may be dynamic, but must be under control of administrators if they wish to avoid the challenge that they are subsidizing immoral or unethical (or indeed, illegal) activity. By limiting the solution to only those sites selected as being valuable to the organization’s target user community, they can show that they are acting in good faith in attempting to establish acceptable boundaries.
II. Goals
A. Be able to successfully bypass censorship
This, of course, is the whole point. Any solution that cannot be put in the hands of the user community in such a way to enable them to view the restricted information is no solution at all. For instance, changing IP addresses every hour is quite likely to be able to out pace any censor's efforts, but is also just as likely to put the resource out of reach of all but the most technically sophisticated and dedicated users (who would themselves be in a position to implement their own solution, further reducing the success).
B. Be easy for the target community to use
The most obscure implementation that cannot be snooped is valueless if the users are unable to operate it. This implies that the tools used must be friendly and easy to operate, ideally not requiring any effort on the part of the user community. This of course clashes with A above. By making a solution very easy to use (i.e., locate in the case of an IP morphing web site), you are also making it very easy for the censor to maintain the screening.
C. Scale cleanly as usage increases
Success is a strong factor in many failures in the dot com world. By successfully attracting the millions of potential users in the censored country, and if the resources devoted to the initial implementation are not enough, users quickly become upset and shift their attention elsewhere. If, on the other hand, if huge resources are initially installed upon initiation, maybe the millions do not find the service offered valuable and the resources go underutilized opening room for complaints related to over spending.
D. Limit exposure to accusations of misdeeds
A good solution will be one that limits (ideally eliminates) the possibility that the service can be used for illegal, immoral, or unethical efforts, in either the host organization or censored (China, for example) countries. Forces in either country could make great political hay if it were shown that the host organization was subsidizing these sorts of activities. The very efforts expended in attempting to obscure legal and valid usage can often be leveraged unchanged by those with less honorable intentions. Since the very success of bypassing any censors is likely to breed discontent in that agency's government, it may be important to minimize any additional antagonisms by planning ahead to minimize them.
III. Implementations
Many people make the direct association of the Internet with the World Wide Web. While the Web cannot exist without the Internet, the Internet existed fine for years before the advent of the Web (or more specifically, the implementation of HTTP). There are many forms of electronic communication that utilize the Internet. While all of these forms are subject to blocking by IP addresses, some of them are inherently very hard to block that way. For instance, email deliveries can take any of a number (that may reach millions) of different paths to reach the end user. Since you cannot determine in advance what the path will be for a given message, it is often difficult to block simply by IP address. Usenet groups make information available in an analogous way as the web does, though without most of the multi-media content. Mailing lists, or groups of email addresses that are automatically posted as something new comes along, provide a party line of sorts, where anyone can read all messages, and anyone can post a message, but all content is transferred via email. It is possible to send and receive information via chat or instant messaging, and that process can even be automated. In all cases, one must be sure that the community receiving the information is interested, or you can create a bad reputation for yourself. All of these strategies have some weaknesses, many of which are interrelated. For instance, Usenet can be blocked via IP screening and so can mailing lists (though to a much lesser extent due to the bouncing nature of email). Chat software almost always runs off some set of central servers, so is quite vulnerable to IP screening. In the case of mail lists and chat, there is the Spam issue. Getting a list of prospective recipients would require some effort, maintaining that list even more, but reacting to those that receive the content and are not interested in it in such a way to deflect any ill will that may be felt can be the greater challenge. If it is trivial to remove yourself from the list, then it will be trivial for the censoring agency to create its own list and remove most of the recipients. If it is an effort or is complex to remove an address from the list, then the ire of the unwilling recipient is raised, creating ill will toward the agency responsible for initially creating the list.
IP screening is mentioned often as the method of choice for blocking content. It is probably the most efficient and cost effective method, but it is possible and practical to screen unencrypted content by examining each communication stream. It is suspected that the US government’s NSA is capable of doing so, and there has been a lot of publicity surrounding the FBI’s Carnivore snooping device, but for most situations, it is not practical to screen content. With very little dedication on the part of the people transmitting information, it is possible to defeat almost all content screening devices. Encryption is the easiest and most straightforward method, but even if the censoring agency attempts to block all encrypted information, that information can just as easily be hidden in images, and if that were blocked, it could be hidden in plain site in several well-known encryption methods. Ultimately, the censoring agency has to block all cross border communication to eliminate the information flow, something that is more or less acceptable to different governments. Since IP screening is done at the hardware level and is very fast, it is the choice of most censors, but changing addresses can easily defeat it. That is where the human element comes in. If the IP address changes faster than the humans of the censorship agency can locate and program into their hardware, then the information can get through. If the censors can keep pace with the changing addresses, then the information cannot get through. Success at changing the IP address brings us back to the difficulty of making the new address available to the end user quickly without simultaneously notifying the censoring agency.
Triangle Boy
Triangle Boy (Tboy, please see http://www.safeweb.com/tboy_service.html for some information), an implementation that has been used specifically to bypass censorship already, and addresses many of the concerns outlined above. It is a central resource that acts as a proxy by rewriting the low-level communication packets and fools the receiving entity into thinking the data was received from the actual location to which the request was sent. The heart of the Tboy implementation is the use of a small program to run on some unknown (to the censors, but must be known to the users) IP address. The user in the restricted area accesses the restricted content by making their request via one of these Tboy servers scattered about the Internet. That program then forwards the request to the central resource where it is processed then sent back to the originator with the spoofed packet information. This enables the important code associated with the processing of the requested information to be centrally located and controlled, thus easily allowing for upgrades to respond to fixes or enhancements. The main issue with the Tboy is the same for all implementations: how to disseminate the locations of the Tboy IP addresses without simultaneously providing that information to the censoring agency. Secondarily is the resources needed at the central server. Most web browsing anonomizers have been forced off the (free) web not by censorship, but by success. The very success that these organizations are seeking is what swamps their resources forcing them either into expensive upgrades or reducing use to the consumers. By having a central resource, implementers are tasked with attempting to install the appropriate levels of hardware and software to meet the anticipated demand while not being vulnerable to charges of overbuilding (in the case that the service is under utilized) or lack of forethought (in the case where the service is over utilized).
IV. Recommendation
Overview
The recommendation of this paper is custom designed software that restricts the use to a selected set of destinations (thus sidestepping issues related to immoral or illegal activity), is distributed (thus minimizing or eliminating the need for expensive central resources), and with a successful initial marketing campaign, would have thousands, perhaps tens of thousands, of locations implemented in a random and unpredictable way. A key part of making this resource available relies on not only peer-to-peer transmittal of the censored information (much like Tboy without the central server), but on peer-to-peer communication of the location of the resources. One of the key advantages of this implementation is that it relies on no central agency to distribute it, nor on any central agency to notify end users of its availability. For example, the program(s) are made available via the organization’s web sites, both as source code and as several easy to install precompiled executables and that location is advertised to the friends and family of the censored groups OUTSIDE the censored area (these people are the ‘installation community’). As these people have strong ties to the ones 'back home', they have the incentive to make their own personal resources (i.e., their web space or home computer) available to a small user community of their censored compatriots. They install the program on their computer resource, and then notify their friends and family (the user community) that the resource is there via whatever means available (phone, email, fax, etc.) The censored user community now has access to information that was previously restricted, and unless there is a member of the censor agency amongst the group, the site should be available for some time. In the event that the site becomes very popular, the uncensored installer has the option of increasing or reducing resources according to their own personal desires. If this scenario is played out thousands of times, then the potential exists for a nearly unscreenable number of simultaneously operating programs all appearing in a random and unpredictable manner. Another key portion of this solution is less important, but represents a significant cost issue. By eliminating the central resource, scaling issues are eliminated entirely along with their associated expenses. Below is a graphic depicting the relationships.
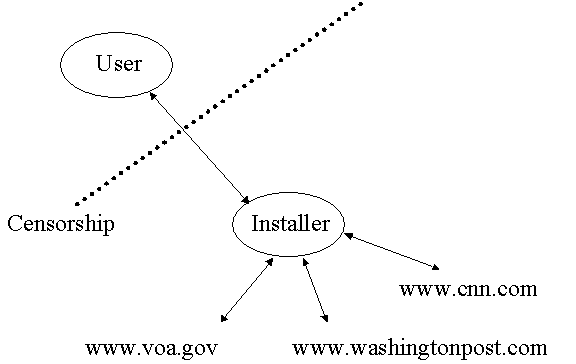
Description
This program would actually come in two versions; one is that of a CGI program that could be loaded on any exiting web server, and another is a very stripped down web server that only handles a fraction of the details a normal web server would. Each one will be programmed separately, but there will be much in common between them so that they can be written in tandem.
In its simplest form, the programs just listen for requests directed toward them, parse the request to determine its true location, then reissue that request on behalf of the requestor and rewrite (if necessary) the response before returning it back to the requestor. In and of itself, this technology is well established and has existed for quite some time (for example, proxy and redirection servers). The coding is inherently simple; though successfully parsing and recognizing all the possible internal links within a given HTML page can be a daunting, continually ongoing task. However, by not attempting to be in a position to address all of the latest web based technology, having the written content but possibly missing some graphical add-ons (such as Flash), will allow an organization to meet its needs to make information available to the censored groups. Web site restriction is done by coding directly into the program the available lists of sites that can be visited. While releasing the program in source version enables this restriction to be easily bypassed, it would require some technical ability on the part of the installer and if cryptographic hashes are kept for the 'official' compiled versions, the organization could easily demonstrate that the program had been modified outside of their control.
Potential add-ons or enhancements that may be desirable in the future (and could be supplied via the installation community, see the section on Open Source below):
- Caching of content to allow the program to reduce the need for making multiple requests for the same material.
- Encryption of the URL requested, which would make any proxy logs fairly useless for mining to locate users.
- Encryption (which would be automatically supplied by the CGI program if installed on a secure web site) could be added to content as it passes to and from the user's computer.
- Encryption of any data handled by the actual server/CGI handling the request. This is not viewed as a significant issue, as the server/CGI would already be outside the censoring country.
COTS vs. Custom
Commercial of the shelf (COTS) software has the initial appeal of quick implementation and deployment. However, when an entity is attempting to use the COTS product in a way that is somewhat outside its original intended purpose, there is often a need for customization ‘glue’ software to join unrelated pieces into a whole. If the original problem is fairly simple and easy to define (but is not directly applicable to a COTS product), the cost and time devoted to the ‘glue’ may be better utilized in a custom designed and implemented software product. One large benefit of doing so is any changes needed by the organization can be addressed immediately. One large drawback is any changes require ongoing investment by the organization. However, upgrades and newer versions of COTS products are often not free, and the cost of the different upgrade strategies may balance out. Another benefit of custom software in this case could be the ability to track usage of the program by its browser version tag, which could be customized for each implementation of the program, providing readily mineable information regarding usage by the target audience.
Open source
By making the source written for this application available directly to the installation community, the organization can take advantage of potential free labor via the open source movement. As people use the application, they may find bugs and desire enhancements. By making the source available, some portion of the community is likely to implement their own fixes/changes, and polite requests for those changes may be rewarded by the donation of that effort back to the main repository. That way, a relatively simple initial program could be greatly enhanced and expanded by the donated efforts of the interested ‘installation’ community. The typical downsides of open source code would still be in effect: multiple versions, possibly rapidly mutating versions that the organization would have no control over, as well as problems with people attempting to work beyond their technical boundaries. However, the ongoing maintenance of the project could be reduced one part-time person who would collect and collate bug reports and enhancement requests. If the community responded with working code, then all the maintainer would have to do is ensure that integration and regression testing revealed no problems.
Customization to country
In order to better target specific censored counties, specifically tailored versions of an implementation could be developed for each country of interest (this may be difficult to do with a COTS product). That way, the installation instructions can be customized as well as the list of sites available via the program. The main page of the program could be designed in keeping with the sensitivities of target user community, yet would leave the core of the program nearly untouched.
Estimates
Below are some very ballpark cost estimates for the design and deployment of this recommended software:
- Write the code - 4 man months
- Test the code - 3 man months
- Document the code - 1 man month
- Document the installation - 2 man months
- Document the usage - 1 man month
- Locate the ‘installation community’ - 4 man months (guess!)
- Possible redesign of the organization’s content (to accommodate simplicity of initial program) - unknown
Proof of concept
A very simple proof-of-concept has been written (in the C language) and deployed as a CGI program. The interested reader may visit the site at http://sol-system.com/cgi-bin/censor/censor.cgi. The source is available at http://sol-system.com/censor/. Please keep in mind that this is a work in process and if it is not working, please try back later or send your comments to koxenrider[at]sol[dash]system[dot]com. The goal of this proof of concept is to rewrite web pages so that any links contained within (such as “IMG SRC”, “A HREF”, etc.) are redirected through the CGI program for processing. The initial web page should be a list of links that will work via this program (such as voa.gov, washingtonpost.com, CNN.com, etc.), and by clicking on one of those links the user should be directed to that sites primary web page. They should then be able to navigate that sites web pages just as if they had surfed there directly.
Compare and contrast Tboy
The Triangle Boy implementation as described above has the allure of being a COTS product. In addition, it may be possible to combine it with several other COTS products in a fairly straightforward way to provide the ‘accept only’ screen of usage to block people from using the service for illegal, etc. uses. It does rely, however, on the bulky central server, which may be quite expensive to maintain and upgrade if the success most organizations are seeking is realized. It also relies on the distribution of the Triangle Boy servers on some number of unknown and unguessable locations across the Internet, and is subject to the main problem of how to disseminate the locations of the Tboy servers without notifying the censoring agencies. Tboy, by operating with the central resource, enables a fairly easy migration path to address fixes and enhancements. Having said all that, the program described in this paper addresses all the weaknesses of Tboy, particularly the problem of how to notify the user community without notifying the censoring agency. One could argue that by encouraging the ‘installation community’ to install Tboy servers on their machines you would achieve the same effect. However, many people with the sophistication necessary to install and configure the Tboy (no matter how simple and easy, they are making their computer resources vulnerable), many may question the size and complexity of the program executable (close to a megabyte according to Tboy literature, as opposed to less than 50K for the proof of concept as developed so far). The program proposed herein is intended to be very simple and its goal is to make information content available. Tboy is intended to make the full multi-media experience of the WWW browsing experience as seamless as possible while maintaining the full obscurity of the person browsing. Tboy’s reliance on large central resources may be so expensive, that the full cost of implementing this program could be less than the cost of the Tboy hardware. In the event that the demand is demonstrated by use of this program, but the program is deemed to limiting, at least there would be proof of the demand to demonstrate the hardware resources needed for implementation of another idea such as Tboy.